 The x86 server wars heated up significantly in March, with the end of the month seeing a major processor launch from each vendor: AMD launched its 12-core Opteron 6100 processor, codenamed Magny-Cours, on the 29th, and Intel then finished off the month with the launch of the 8-core Nehalem EX Xeons.
The x86 server wars heated up significantly in March, with the end of the month seeing a major processor launch from each vendor: AMD launched its 12-core Opteron 6100 processor, codenamed Magny-Cours, on the 29th, and Intel then finished off the month with the launch of the 8-core Nehalem EX Xeons.These were pretty major launches, but I've covered Nehalem EX previously so I want to focus on AMD this time around.
AMD actually launched ten different processors at a range of clockspeeds (1.7 to 2.3GHz) and core counts (8 and 12); all of these parts make up the Opteron 6000 series, which is aimed at two- and four-socket configurations. These two configs represent the bulk of the server market, and AMD is aiming to be the value player here.
In terms of microarchitecture, the new Opterons don't differ significantly from their predecessors, or indeed from the previous few generations. The addition of support for virtualized I/O is the main change a the core level, a change that brings AMD up to par with Intel's Nehalem parts in their level of virtualization support.
At the level of what I'd like to call "macroarchitecture"—meaning the arrangement of cores, I/O, cache, and other resources on the processor die—there are some significant improvements.
The shared cache for the 8-core parts is 17.1MB, while the 12-core weighs in at 19.6MB.
On the memory front, the new Opterons boast support for four channels of DDR3—that's a lot of aggregate memory bandwidth across two or four sockets. For I/O, each package has four HT 3.0 (x16) links; this amount of I/O bandwidth is needed because there are so many cores per socket. In fact, moving out to the system level, you can see where AMD put most of its engineering effort.
DirectConnect 2.0
One of the key ways that AMD is amping up the bang-per-buck is by taking a route that it had previously made fun of Intel for: sandwiching two n-core dies into a single package (a multichip module, or MCM) and calling the resulting part a 2n-core processor. The 12-core is two six-core dies, and the 8-core part is two four-core dies (actually, it's two six-core dies with some cores disabled, an approach that helps get yields up and costs down).
Back when Intel started doing this MCM-based multicore approach in the waning days of the Pentium 4 era, its impact on system architecture was a lot more straightforward. But AMD's NUMA system architecture, where the on-die memory controller means that the memory pool is distributed among all the sockets in a multisocket system, complicates the MCM approach. This is because the number of NUMA nodes no longer equals the number of sockets. AMD's answer to this problem is called Direct Connect 2.0.
Take a look at the diagram below, which shows the I/O and memory buses in the Magny-Cours part. You can see that each individual Magny Cours die (or "node," from the perspective of NUMA topology) has two memory controllers and four HT 3.0 controllers.
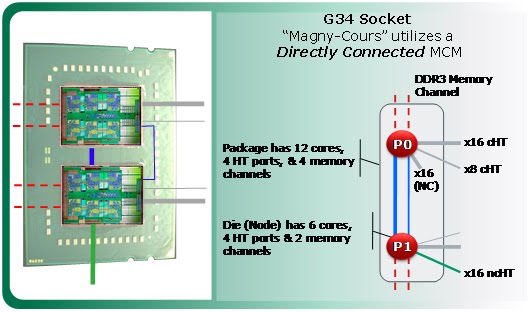
The two memory controllers on each die connect directly to the pool of DDR3 that hangs off of each socket, which gives each socket its four total DDR3 lanes.
The way the HT link bandwidth is divided up in a two-socket config is a little non-obvious, but you can see what's going on from the diagram. The controllers split the link bandwidth for each die/node into three x16 links and two x8 links. One of the x8 and one of the x16 are then combined to make what's essentially an x24 link, which is used for directly connecting the two dies that are in the same package.
Another x16 link goes out to connect to the first die in the other socket, and the remaining x8 link connects diagonally to the second die in the other socket. The fourth remaining x16 link on one of the dies is not connected to anything, and on the other die it's used for I/O. The diagram at right attempts to illustrate how this works—it's not great, but if you stare at it for a minute it makes sense.
What's new about Direct Connect 2.0 (as opposed to Istanbul's 1.0 version) are the diagonal links, which let each node connect to two other nodes. Direct Connect 1.0 was missing the diagonal links, so if memory was in the wrong pool a node might have to make two hops to get it, instead of just one. Of course, the diagonal links are half the bandwidth of the regular links, but you can't have everything.
With so many cores per socket, congestion is still going to be a problem, despite the four HT 3.0 links per node. This being the case, AMD uses a technology called HT Assist to reduce inter-core traffic by cutting back on cache snoops among the sockets, so that helps mitigate some of the traffic congestion that could crop up with all of those cores and off-die links.
Despite the drawbacks of the MCM approach, Intel proved with its own dual-die products that the strategy works, especially if you're targeting cost and not just raw performance. MCMs are also great for when you want to pack a lot of compute power into a smaller, cheaper system, and you're willing to compromise a bit on the memory performance for certain kinds of latency-sensitive, write-intensive workloads. Specifically, Magny-Cours should make for a great HPC platform, because it offers a lot of plenty of hardware per socket, per dollar, and per watt, and that's just what you need to put together a cluster of machines that can grind through heavily data-parallel workloads.
Databases are probably a different story, especially when you compare Magny-Cours to Nehalem EX's buffer-enabled memory subsystem, which lets you cheaply cram loads of memory onto each socket. It's also the case that these types of workloads tend to have more coherency traffic, because different nodes may be accessing the same region of memory. In this case, the balance may tip in Intel's favor.
In all, though, the Magny-Cours launch is a huge one for AMD, and its platform-level innovations like Direct Connect 2.0, support for virtualized I/O, power efficiency, and relatively low cost should keep AMD in the server game. And staying in the server game has been AMD's number one survival priority in the past two years. I pointed out at the end of 2009 just how much other business AMD has thrown overboard as the company shrank back into its core x86 server and GPU businesses, and this new server platform reflects that single-minded focus. AMD's processors may not have the raw per-core performance that Intel's Nehalem boasts, but the company is doing a lot at the macroarchitecture and system architecture levels to narrow that gap.
Source: Arstechnica.com

